C 언어에서 문자와 문자열이 메모리에 어떻게 저장되는지 이해하는 것은 시스템 프로그래밍의 기초다.
특히 디버거(GDB)를 통해 실제 메모리 주소에 접근하여 바이너리 데이터를 확인하면, 추상적으로 알고 있던 변수들이 물리적으로 어떻게 배치되는지 시각적으로 파악할 수 있다.
오늘 수업에서는 C언어로 프로그램을 작성하고, GDB를 활용해 메모리 구조를 분석하는 것을 배웠다.
1. 소스 코드 작성
먼저 문자와 문자열 배열을 포함하는 간단한 C 소스 코드를 작성한다.
단일 문자 변수와 두 개의 서로 다른 문자열 배열을 선언하고 출력하는 코드다.
소스 코드 (gdbchar.c)
#include <stdio.h>
int main()
{
char ch1 = 'A';
char message1[] = "ABCDE";
char message2[] = " A B \nabcd";
printf("ch1: %d %c\n", ch1, ch1);
printf("%s %s\n", message1, message2);
return 0;
}- char vs char[] : char는 1바이트 공간에 문자 하나를 저장하고, char[]는 여러 개의 char 공간을 연속적으로 할당받아 문자열을 저장한다.
- 문자열 끝의 널 문자 : C 언어에서 모든 문자열의 끝에는 '문자열의 끝'임을 알리는 NULL 문자(\0, ASCII 0)가 자동으로 삽입된다. 따라서 "ABCDE"는 5글자지만 메모리상에는 6바이트를 차지한다.
2. 디버깅 옵션으로 컴파일
작성한 소스 코드를 실행 파일로 변환한다.
디버깅을 위해 컴파일 시 특수한 옵션이 필요하다.
$ gcc -g -o gdbchar gdbchar.c
- gcc : GNU C 컴파일러.
- -g : 바이너리에 디버깅 정보를 포함한다. 이 옵션이 있어야 GDB에서 소스 코드의 변수명이나 라인 번호를 확인할 수 있다.
- -o gdbchar : 생성될 실행 파일의 이름을 gdbchar로 지정한다.
- 64비트 컴파일 : 별도의 -m32 옵션을 주지 않으면 현재 시스템의 기본 아키텍처(64비트)로 컴파일된다.
3. GDB를 이용한 런타임 디버깅
프로그램이 실행되는 동안 메모리 내부를 들여다보기 위해 GDB(GNU Debugger)를 사용한다.
$ gdb -q ./gdbchar
(gdb) b main # main 함수에 중단점(Breakpoint) 설정
(gdb) r # 프로그램 실행(Run)
(gdb) n # 다음 줄 실행(Next), 변수 선언 완료까지 반복
- n (next): 소스 코드의 다음 한 줄을 실행한다. 함수 내부로 들어가지 않고 현재 레벨의 다음 줄로 이동한다.

먼저 ch1의 주소를 출력해 본다.
(gdb) p &ch1
$1 = 0x7fffffffdd26 "AABCDE"
흥미로운 점은 p &ch1을 했을 때 "AABCDE"라는 문자열이 출력된 점이다.
gdb에서 p &ch1을 입력했을 때 "AABCDE"라는 결과가 나오는 이유는 메모리 배치(Memory Layout)와 C언어의 문자열 종료 방식 때문이다.
1️⃣ GDB의 문자열 출력(-p) 매커니즘
먼저 GDB의 p (print) 명령어는 인자로 전달된 주소의 자료형이 char *(문자열 포인터)인 경우, 해당 주소부터 시작하여 NULL 문자(\0, 값 0)를 만날 때까지 메모리를 순차적으로 읽어서 문자로 출력한다.
⭐NULL 종단 문자(\0): C언어에서 문자열의 끝을 나타내는 약속이다. 메모리에는 데이터가 연속해서 들어있기 때문에, 어디가 문자열의 끝인지 알려주는 표식이 반드시 필요하다.
- 시작: GDB는 &ch1 주소(0x...26)로 간다. 거기엔 'A'가 있다.
- 진행: 다음 칸(0x...27)을 본다. 아직 NULL이 아니므로 거기 있는 'A'를 읽는다.
- 반복: 계속해서 'B', 'C', 'D', 'E'를 읽는다.
- 종료: 0x...2c 주소에서 드디어 \0(NULL)을 발견하고 읽기를 멈춘다.
결과적으로 ch1의 값인 'A' 하나와 message1의 값인 "ABCDE"가 합쳐져서 화면에는 "AABCDE"로 보이게 되는 것이다.
2️⃣ 메모리 배치 (Stack Adjacency)
위와 같은 결과는 메모리상에서 ch1 바로 다음에 message1이 위치하기 때문에 나오는 것이다.
이어서 message1과 message2의 주소를 찍어보면 더 명확해진다.
(gdb) p &message1
$2 = (char (*)[6]) 0x7fffffffdd27
(gdb) p &message2
$4 = (char (*)[11]) 0x7fffffffdd2d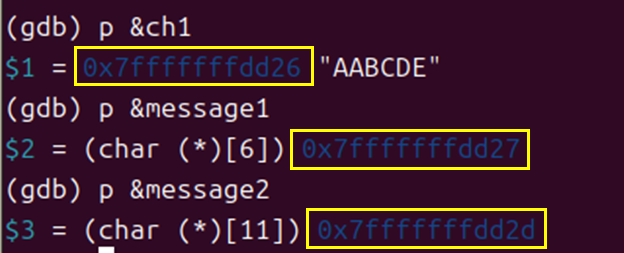
이는 메모리상에서 ch1 바로 다음에 message1이 위치하고, message1 바로 다음에 message2가 위치하기 때문에 그렇다.
프로그램이 실행될 때 지역 변수들은 스택(Stack) 영역에 할당된다.
소스 코드에서 변수를 선언한 순서에 따라 메모리에 인접하게 배치되는데, 방금 전에 gdb에서 각 변수의 주소값을 확인했을 때 다음과 같이 나왔다.
- ch1의 주소: c (1바이트 크기)
- message1의 주소: 0x7fffffffdd27 (6바이트 크기: "ABCDE" + \0)
- message2의 주소: 0x7fffffffdd28 (11바이트 크기: "ABCDE" + \0)
주소를 보면 ch1 바로 다음 주소(+1)에 message1이 시작되고, message1의 주소에서 +6을 한 지점에서 message2가 시작됨을 알 수 있다.

3️⃣ x 명령어를 이용한 메모리 상세 분석
GDB의 x (Examine) 명령어는 메모리 주소의 내용(바이트 데이터)을 원하는 형식으로 출력해준다.
x 명령어 사용법
x/[개수][형식][단위] [시작주소]
- 개수(n): 출력할 메모리 유닛의 개수. (생략시 1)
- 형식(f): 데이터를 어떻게 보여줄 것인가? (x: 16진수, d: 10진수, c: 문자, s: 문자열)
- 단위(u): 한 번에 읽을 데이터의 크기. (b: 1바이트, h: 2바이트, w: 4바이트, g: 8바이트)
🟢Step 1. 바이트 단위 문자형 출력 (x/cb)
가장 직관적인 방법은 메모리를 1바이트씩 끊어서 문자(c)로 확인하는 것이다.
이를 통해 변수들이 메모리상에 얼마나 인접해 있는지, 그리고 문자열의 끝을 알리는 NULL 문자가 어디에 위치하는지 한눈에 파악할 수 있다.
# ch1의 주소부터 20개의 바이트를 문자 형식으로 확인
(gdb) x/20c &ch1
0x7fffffffdd26: 65 'A' 65 'A' 66 'B' 67 'C' 68 'D' 69 'E' 0 '\000' 32 ' '
0x7fffffffdd2e: 65 'A' 32 ' ' 66 'B' 32 ' ' 10 '\n' 97 'a' 98 'b' 99 'c'
0x7fffffffdd36: 100 'd' 0 '\000' ...
💡GDB에서 출력 형식을 c(문자)로 지정하면, 별도의 단위(b, h, w, g)를 명시하지 않았을 때 기본적으로 1바이트(b)를 단위로 설정한다. (문자는 기본적으로 1바이트이기 때문) 그래서 x/20c만 쳐도 GDB는 내부적으로 x/20cb로 알아듣고 동작한다.

- 데이터의 연속성: 0x...26 번지의 ch1('A') 바로 뒤에 message1의 'A', 'B', 'C', 'D', 'E'가 공백 없이 이어지는 것을 볼 수 있다.
- 종단 문자 확인: 0x...2c 번지에서 0 '\000'(NULL)을 발견할 수 있다. 이는 message1의 끝을 의미한다.
- 제어 문자: 0x...32 번지의 10 '\n'은 소스 코드에 삽입한 개행 문자가 실제 메모리에서는 10진수 10(ASCII LF)으로 저장됨을 보여준다.
GDB가 char 형식(x/c)으로 메모리를 보여줄 때 아스키 코드(10진수)와 문자 부호를 나란히 표시하는 이유는 char 자료형이 원래 1바이트(8비트) 크기의 정수를 담는 자료형이기 때문이다.
우리가 'A'라고 코드를 짜도, 실제 메모리 칩에는 65(2진수로 01000001)라는 숫자가 기록된다.
즉, 디버거는 편의를 위해 65 'A'라는 출력은 "이 주소에는 10진수 65가 들어있고, 이건 문자 'A'를 의미한다"라고 두 가지 해석을 동시에 제공하는 것이다.
🟢Step 2. 4바이트 단위 16진수 출력 (x/xw)
이제 데이터의 단위를 키워 4바이트(Word)씩 16진수(x)로 출력해 본다.
이 방식은 시스템 소프트웨어나 리버스 엔지니어링에서 메모리 덤프를 확인할 때 가장 많이 사용된다.
# message1의 주소부터 2개의 워드(4바이트씩 2개 = 8바이트)를 16진수로 확인
(gdb) x/2xw message1
0x7fffffffdd27: 0x44434241 0x41200045

🌀 41, 42, 43...이 의미하는 것 : 아스키(ASCII) 코드
컴퓨터는 'A'라는 글자를 직접 저장할 수 없기 때문에 모든 문자에 숫자를 매겨둔 아스키 테이블을 사용한다.
| 문자 | 10진수 (우리가 쓰는 숫자) | 16진수 (GDB가 보여주는 숫자) |
| 'A' | 65 | 0x41 |
| 'B' | 66 | 0x42 |
| 'C' | 67 | 0x43 |
| 'D' | 68 | 0x44 |
즉, GDB가 출력하는 41, 42, 43은 각각 'A', 'B', 'C'를 16진수로 표현한 것이다.
🌀왜 순서가 44 43 42 41로 뒤집혀 보일까?
이 순서는 gdb에서 x 명령어를 어떤 옵션으로 줬느냐에 따라 달라진다.
바이트 단위로 볼 때 (x/xb)
메모리를 1바이트(한 칸)씩 차례대로 읽으면 우리가 아는 순서대로 보일 것이다.

워드 단위로 볼 때 (x/xw)
하지만 GDB에서 x/xw(4바이트를 한 덩어리로 보기) 명령을 내리면, 컴퓨터는 리틀 엔디언 방식을 사용한다.
이 방식은 "낮은 주소에 있는 값을 숫자의 맨 뒤(하위 바이트)에 둔다"는 규칙이다.
(예전에 리틀 엔디언에 대한 내용을 정리한 포스팅이 있다.)
- 가장 낮은 주소(27)에 있는 41을 맨 뒤로 보냄.
- 그다음 주소(28)에 있는 42를 그 앞에 둠.
- ... 이런 식으로 쌓이다 보면 결과적으로 0x44434241이라는 하나의 숫자로 보이게 되는 것이다.


'Journey to Security > C언어' 카테고리의 다른 글
| 비트 연산(Bitwise Operation) + 2의 보수 개념 (0) | 2026.02.15 |
|---|---|
| C 주소 전달 메커니즘: scanf 원형과 작동 원리, 메모리 구조 (0) | 2026.02.14 |
| C언어 필수 디버깅 도구 gdb 기본 사용법과 16진수 표현 이해하기 (0) | 2026.02.13 |
| C언어 char 배열의 메모리 할당 및 문자열 초기화 메커니즘 (feat. VS Code 디버거) (0) | 2026.02.11 |
| VSCode로 C 코드 디버깅하기 (0) | 2026.02.10 |